手把手教你,怎么在dify中配置自定义的模型
- AI相关
- 时间:2026-01-27 18:53
- 740人已阅读
🔔🔔好消息!好消息!🔔🔔
有需要的朋友👉:微信号
背景描述:
因为本地部署了qwen3-vi:latest。想要在dify中使用,我们知道ollama类型的是不支持qwen3-vi:latest。所以,这里就得用到添加自定义模型了。具体操作步骤如下:
在Dify中添加自定义模型主要有两种方式:一是通过内置的兼容供应商通道(如“OpenAI-API-compatible”或“Ollama”)快速接入;二是通过Dify的后端配置实现更深度的自定义,适合私有化部署或高级开发。
🔧 通过“OpenAI-API-compatible”通道接入
如果你的自定义模型服务提供了标准的OpenAI API兼容接口(例如,很多云厂商的模型服务或自行封装的模型接口),这是一种最直接的方法。
进入设置:登录Dify,点击右上角 “设置” -> 左侧 “模型供应商”。
选择供应商:找到并点击 “OpenAI-API-compatible” 卡片上的“安装”或“配置”按钮。

如果没有添加到话,需要先添加上:
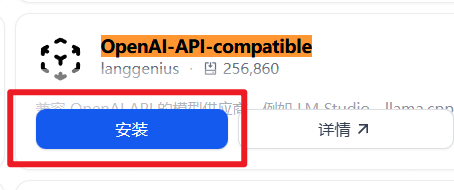
等待安装完成之后,字啊供应商列中就可以看到了: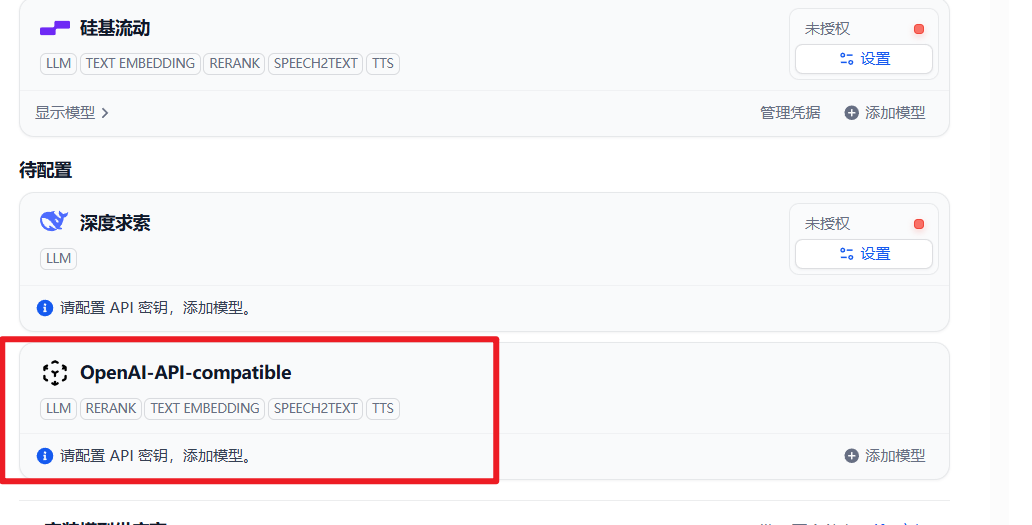
点击添加模型。操作如下:
填写配置:在配置页面中填写以下核心信息:
模型名称:自定义一个名称,如 “My-Custom-Model”。
API密钥:输入你的模型服务所需的密钥。有些服务可能需要两个密钥,其中一个以“Bearer ”为前缀,配置时通常不需要带这个前缀。
API地址:填写模型服务的完整基础URL(例如
https://api.your-model.com/v1)。注意地址中通常不包含/chat/completions等具体端点路径。
🖥️ 通过“Ollama”通道接入本地模型
如果你使用 Ollama 在本地电脑或服务器上运行模型(如Llama 3, DeepSeek等),这是官方推荐且非常简便的方法。
部署Ollama:确保Ollama服务已在你本地或某台服务器上运行,并已拉取所需模型。
进入Dify设置:在Dify的“模型供应商”页面,找到 “Ollama” 卡片。
填写配置:
模型名称:填写你在Ollama中使用的模型名称,例如
llama3:8b或deepseek-r1:7b。基础URL:如果Dify和Ollama在同一台机器,通常是
http://localhost:11434;如果在不同机器,需填写Ollama所在机器的IP地址。API密钥:本地运行的Ollama通常不需要API密钥,此栏可留空或随意填写。
⚙️ 通过后端配置实现高级自定义(开发部署)
对于私有化部署且需要接入非标准接口模型(如ChatGLM、Qwen等)的场景,可以通过修改Dify的后端代码配置文件来实现。
确认模型服务:确保你的私有模型服务能提供 HTTP/REST接口,且其输入输出格式最好能与OpenAI API规范兼容。
修改配置文件:在部署Dify的服务器上,找到后端配置文件(如
config.py),在MODEL_PROVIDERS部分添加新的模型供应商定义。# 示例:添加一个自定义的本地模型供应商 MODEL_PROVIDERS = { "my_custom_provider": { # 供应商ID "base_url": "http://your-model-server:8080/v1", # 模型服务的API地址 "api_key": "your-api-key-here", # 如有 "model_name": "your-model-name" # 默认模型名 } }重启服务:修改配置后,需要重启Dify后端服务使配置生效。
🧪 验证与应用
无论使用哪种方式添加模型,配置完成后都需要进行验证:
验证配置:添加模型后,可以创建一个空白应用,在LLM节点或右上角的模型选择器中,查看是否能找到你刚才添加的自定义模型。
测试对话:在应用的调试预览区域输入简单问题(如“你是谁”)进行测试。如果模型能正确回复,说明配置成功。
💡 注意事项与技巧
接口兼容性是关键:上述前两种方法都要求你的模型服务提供与OpenAI API兼容的接口。如果你的模型服务不是标准格式,可能需要自行开发一个简单的适配层来进行协议转换。
网络与安全:确保Dify服务器能正常访问你的模型服务地址。如果涉及跨服务器或公网访问,请正确配置防火墙和安全组规则。
模型名称:在Dify中配置的“模型名称”主要用于界面显示和内部标识,与模型服务后端识别的实际模型标识符可能不同,配置时需根据服务商要求填写。
如果你想接入某个特定类型的模型(比如ChatGLM或Qwen),或者遇到了具体的配置错误,可以告诉我更多细节,我能帮你看看是否有更具体的解决方案。